Jackdaw Endpoints
Exposing a DAW to other programs, and to itself
Context / Contents
Jackdaw is my free digital audio workstation (DAW), currently in progress. This post, like all programming, is basically about abstraction; it dissects a very big and useful abstraction (the Jackdaw “endpoint”), addressing in particular some issues related to concurrency.
In my last post, I introduced a problem that arose in the course of developing an undo/redo feature for Jackdaw. I will briefly restate the problem here:
Some project parameters – values that have significance in the DAW project – are associated with GUI components like sliders, which can be used to modify the values. These parameters can usually be modified in other ways as well. For example: a track’s volume can be changed by clicking and dragging a slider that appears on the track interface, by holding Shift + “-” or Shift + “=” while the track is selected, or with mix automation. It can also be changed by executing an undo/redo.
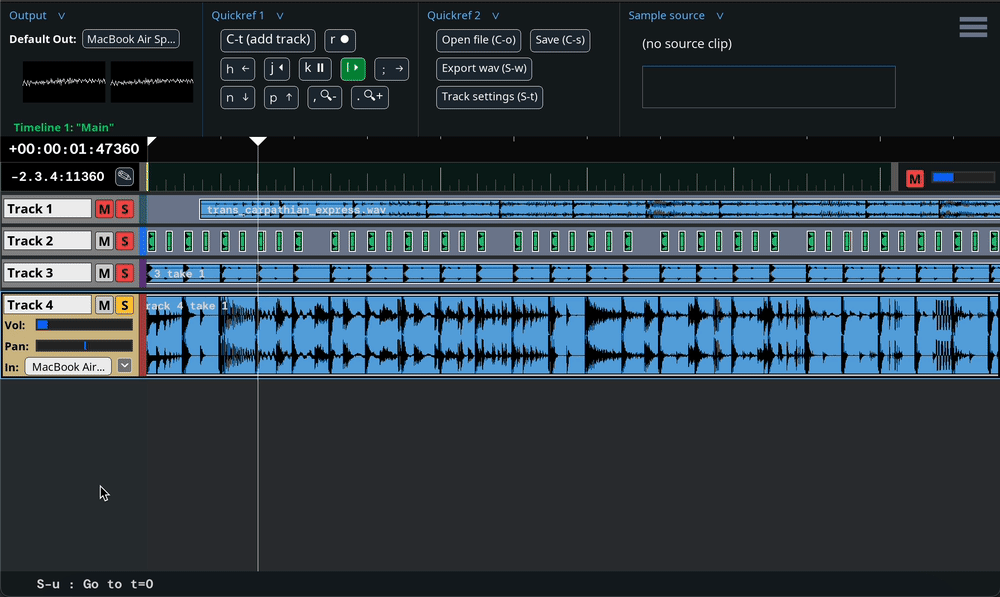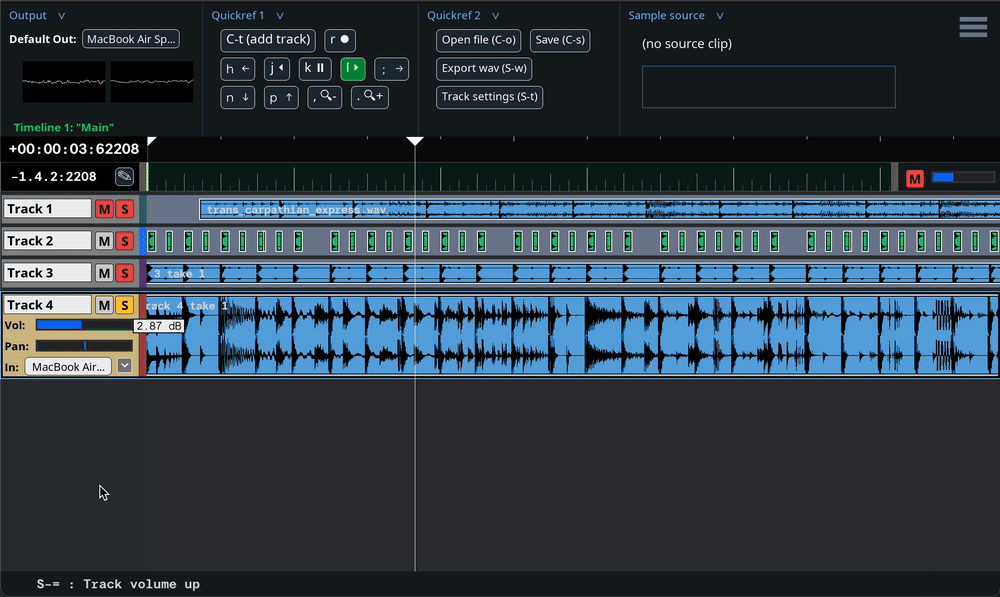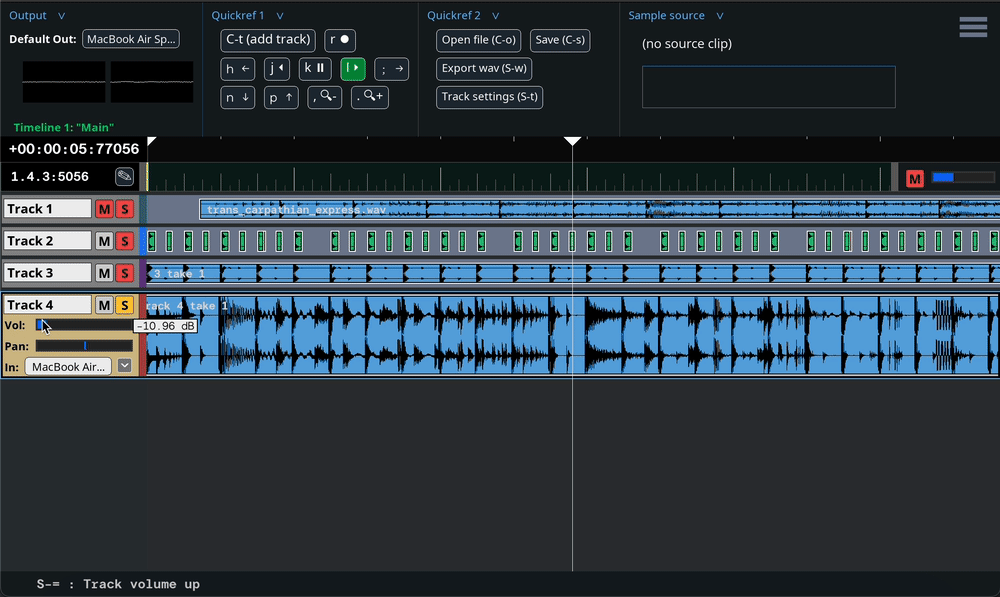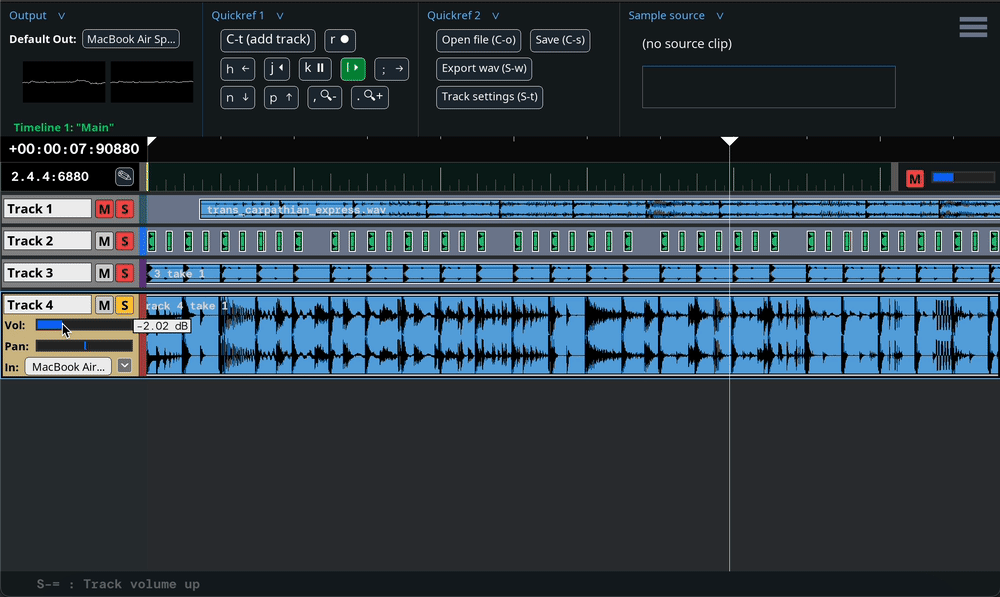
In order to make an undo/redo possible, we must at some point
during the execution of the change push a UserEvent
struct describing how the undo/redo should be executed to a
project-level data structure. But where do we do the push? If we
put it in the slider code, then we also have to put it in the
keyboard code, and in the automation code, and all of these
instances need a way to “find” the associated slider and modify
its appearance to reflect the new value. There ought to be some
symmetry between these different methods of modifying the same
parameter, but the unifying thing here – the track volume – is
just a float living in the parent Track
struct. So how and where do we capture the symmetry?
Clusters of associated behavior
It became clear that some values, like the track volume, are
not just values: they have clusters of associated
behavior. Any time the track volume is modified – regardless of
how it is modified – the associated GUI slider must change, and an
undoable UserEvent must be registered.
Other parameters have other types of associated behavior. If the cutoff frequency of a lowpass filter effect is modified, several things must happen:
- the frequency response of the filter is recomputed;
- a slider representing that cutoff frequency changes appearance, if the slider currently exists;
- an undoable
UserEventis registered.
Endpoints
I had, months before this juncture, mused to a friend that it would be cool to design my DAW with a taxonomy of API endpoints, which could be modified safely from outside of the program. I was thinking a lot at the time about integrating with pure data, and allowing it to control Jackdaw parameters.
I did not anticipate that such a concept would be crucial not just for inter-process communication (IPC), but for internal program operation as well. Here, in this parameters-with-associated-behaviors problem, was the perfect impetus to finally implement endpoints, and with a much richer understanding of their value.
So, thus far, we know that an endpoint must contain a pointer to its target value and pointers to one or more functions that describe the associated behaviors. When an endpoint write operation is triggered, those functions (“callbacks”) will run after the value itself has been modified. That’s all simple enough. But now concurrency enters the picture and wantonly swirls the fresh paint until we can scarcely make out the original subject.
Concurrency
Due to the original IPC concept, it was clear at the outset that endpoint operations would need to be thread-safe. In fact, thread safety generally was due some serious attention; I had been developing the program until this time with an uneasy awareness that there was a class of race conditions that I had quietly deemed acceptable, because in practice they never caused any problems. To return to the archetypal example, I was allowing direct modification of the track volume on the main thread all over the place, with that very same value being read on another thread (the “DSP thread”, which governs real-time audio playback) to scale arrays of audio samples, all with nary a mutex in sight. I’m embarrassed to admit that I still don’t understand theoretically what distinguishes those race conditions that cause crashes or other undesired behavior from the ones that seemingly don’t. (Are float reads/writes reliably atomic on x86 and ARM?) I’ll read up on this eventually, but in the meantime, I knew I could leverage the endpoint abstraction to finally expunge my shameful secret locked (or rather, not locked) in the attic.
What I wanted to avoid, however, was any solution that meaningfully delayed the operation of the “DSP thread.” The real-time audio component of the application needs to run fast, and there are many parameters that can be modified on the main thread that must be read on the DSP thread to process audio for playback. I didn’t want to put locks on every single shared parameter. (More on this at the bottom).
So how do I get read operations on a shared variable to run as fast as possible on the DSP thread without introducing race conditions?
Thread ownership
Fortunately, there is no stringent requirement that reads/writes to these audio parameters be fast on the main thread, or on any thread other than the DSP thread. There is also a convenient design paradigm that we can exploit: both the main thread and the DSP thread run on a loop. This means that a change requested on one thread can be queued for execution on the next iteration of the other thread’s loop. An endpoint can be assigned an “owner thread”, such that a read operation on the owner thread always occurs immediately. This is possible if direct modification of the target variable only occurs on the owner thread.
* Writes:
- on owner thread: in mutex critical region
- on other thread: queued for later execution on the owner thread.
* Reads:
- on owner thread: occurs immediately; no lock
- on other thread: in mutex critical region
Writes on the owner thread – including those that were requested and queued by other threads – still require a lock to guarantee thread safety. But that’s ok; typically, the DSP thread, which owns all sensitive audio-related parameters, only requests read access to those values, and it is the main thread (which handles user inputs) that writes to them. Lock contention will only occur if a read operation is requested on some non-owner thread concurrent with a write operation on the owner thread, and that scenario is generally improbable.
Queued value changes
The list of queued value changes, which is flushed once per loop iteration, must be shared by all threads and and protected by a mutex lock. In a more basic model, where every single shared variable is protected by its own lock, the owner thread would need to lock on every single read of a shared variable; in this model, those reads are lock-free, at the cost of a single lock on the flushing of the queue that occurs once per loop iteration.
Concurrency and callbacks
Those clusters of behavior discussed above – the endpoint callbacks – fall into two main categories:
- Actions that ought to occur on the DSP thread, because they relate to audio processing
- Actions that ought to occur on the main thread, because they relate to the GUI (drawing to the screen)
Therefore, endpoint callbacks are specified per-thread; one each for the DSP thread (the “dsp callback”) and for main (the “gui callback”). Relegating all GUI-related behavior to the main thread and audio-related behavior to the DSP thread regardless of which thread initiates those changes saves us from a lot of granular locking operations and greatly reduces the complexity of the program overall, at the cost of some latency and a somewhat complicated endpoint design.
The callbacks are handled in a similar manner to the value changes themselves. Callbacks that must run on a non-owner thread are queued to be executed on the next iteration of that thread’s loop, after the value has been changed.
Complexity arises when, for example, the main thread writes to a DSP-owned endpoint, but also includes a GUI callback. The GUI callback can’t run immediately, because the target value must first be modified on the DSP thread. Instead, the GUI callback is queued to be queued later, after the value change is done.
| Main | DSP |
|---|---|
| 1. Initiate write | … |
| 2. Queue value change | … |
| … | 3. Execute value change |
| … | 4. Queue GUI callback |
| 5. Execute GUI callback | … |
This design causes latency in most GUI updates related to audio parameters. It might seem like a big cost, given the importance of GUI responsiveness, but in practice, it’s barely noticeable.
Taking stock
So far, we know that an endpoint must store the following:
- a pointer to its target value
- the identity of the owner thread (either main or DSP)
- a DSP callback, if applicable
- a GUI callback, if applicable
- data to be used as arguments to the callbacks, if required
What about undo/redo?
Ah yes. Now we temporarily banish concurrency and unswirl the paint so we can revisit the original subject.
As discussed in the previous post, an undoable event requires instructions on how to execute both an undo and redo of that event. For some such events, these instructions are unique; in other words, new undo and redo functions must be defined for that particular type of event.
But for a large new class of events – namely, endpoint writes – there is enough symmetry that we can handle the undo logic abstractly. This is possible because the individual variations in behavior are already captured in the endpoint callbacks.
At the most basic level, it is quite easy to understand how
this will work: anytime we do an endpoint_write, we
will push a UserEvent that stores both the old and
new value of the target. When an undo occurs, a new
endpoint_write is triggered to reset the endpoint to
the old value, and a redo will do the same, but for the new
value.
We don’t want undo/redo operations to push new
UserEvents themselves (we are not using the emacs
model), and there are some other scenarios where an
endpoint_write should not be undoable, so we
add a boolean undoable parameter to
endpoint_write that specifies whether or not a
UserEvent should be pushed. The calls to
endpoint_write that occur inside the undo/redo
functions will always pass false for that
parameter.
Many parameter changes, like clicking and dragging a slider,
are continuous changes, where a single “event”
encompasses many per-frame endpoint writes. In those cases, a
UserEvent should only be registered when the
continuous change has completed. Therefore, in addition to
endpoint_write, we add
endpoint_start_continuous_change and
endpoint_stop_continuous_change functions to the
endpoint interface. When a continuous change starts, the current
value of the endpoint is cached; the writes that occur during the
continuous change (e.g. with the dragging of the slider) are not
considered undoable; and when the continuous change stops
(when the mouse button is released), a final write occurs that
is undoable, and uses the cached value as the undo
value.
Value ranges and automation
Adding minimum, maximum, and default values to endpoints allows
us to create sliders and automation tracks more or less directly
from endpoints. In my original automation design, details like the
range, default value, and a pointer to the target value were tied
to an AutomationType, which could be one of
AUTO_VOL, AUTO_PAN,
AUTO_FIR_FILTER_CUTOFF, etc. If I wanted to add
support for a new type of automation, I would need to expand the
automation feature to accommodate it. Automations also had their
own logic to account for concurrency.
Now, when the user goes to add a new automation, the program simply displays a list of endpoints associated with the given track, and can create an automation from any of them. In this new design, that list of available automations is also dynamic; if a new effect is added to a track, new endpoints for each of its parameters are registered to the track, and those parameters will appear in the list of available automations. If the effect is deleted, they will disappear from the list.
The Jackdaw API
The immediate impetus to create endpoints was to solve problems in the internal program design, but recall that the prototypical concept was motivated by an interest in allowing Jackdaw to receive inputs from other programs. I knew during the build that once I had endpoints working internally, it would not be too difficult to expose them to the outside world.
All I needed to add was some kind of taxonomic data structure for the endpoints (which would mirror a tree inherent in the program design), a hash table, and a UDP server.
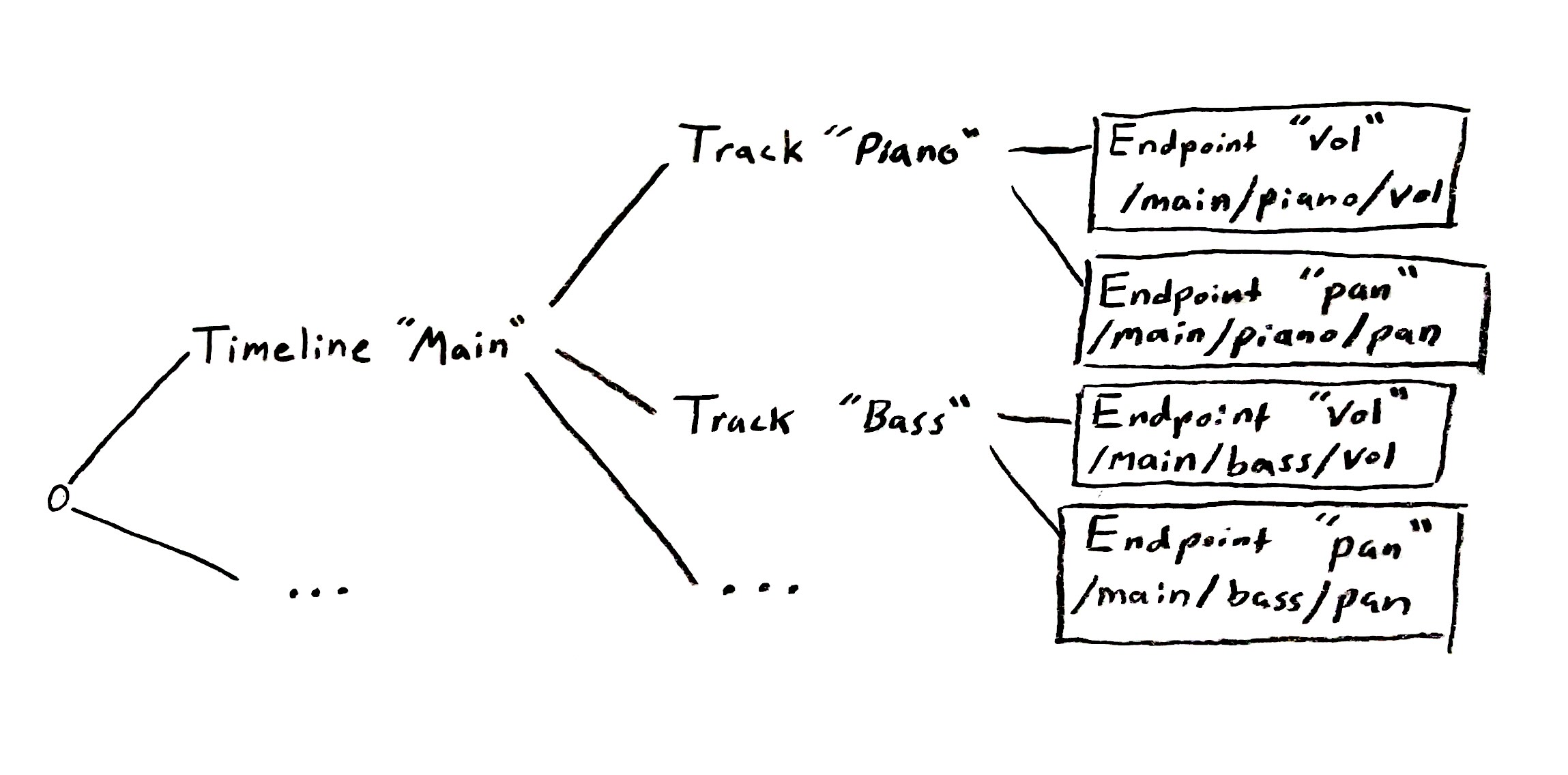
Each endpoint has a “local id” (e.g. "vol",
"pan"), and each node in the tree
(APINode) points to the related object name, like the
track name. The tree lends itself naturally to the filepath-style
route names,
e.g. /{Timeline name}/{Track name}/{Endpoint local id}.
It is these routes that are hashed when endpoints are inserted
into a global hash table. If an object tied to an API node is
renamed, the related routes are reconstructed.
(I learned from friends subsequently that this route syntax is very similar to that used by OSC, but that’s a coincidence. I think it’s just the most natural way to do it.)
The API request syntax is simply the endpoint route followed by a string representing the desired new value. E.g.:
/main/piano/vol 0.765The user can start a UDP server on a port of their choice
(function Start API server, which you can find with
the function
lookup). Incoming messages are parsed into a route and value.
The route is hashed, and if a matching endpoint is found, the
server thread calls endpoint_write to set the new
value.1 That’s it!
This setup can be used for IPC on a single machine, and since it uses a network protocol, it can also be used over the network. Here’s pure data, running an LFO on my macbook, sending UDP datagrams over the network to modify the track pan on an instance of Jackdaw running on my old thinkpad:
Complexity
The endpoint build is a bit of a horror. There are many details I’ve elided in this post for brevity’s sake (believe it or not). I merged the feature several months ago, and in writing this, had some difficulty reading the code and remembering exactly how everything works. I should thoroughly document that code.
On the other hand, I have been using endpoints extensively since implementing them, and writing this post is the first time I have had to reopen the black box. The endpoint abstraction contains a lot of complexity, and silently bears the burden of difficult problems related to concurrency so that I no longer have to.
Is this OOP?
I don’t know. “Data with associated behavior” certainly
sounds like OOP, but I don’t feel that using a language
with classes would particularly behoove me here. It’s worth noting
that, in my design, the endpoint value itself does not live inside
the Endpoint struct; the Endpoint just
points to it. The two live side-by-side in some parent struct:
typedef struct track {
...
float vol;
float pan;
...
Endpoint vol_ep;
Endpoint pan_ep;
...
} Track;I am free to access the track volume directly on the track and
modify it with normal floating point operations where appropriate
(e.g. when loading a project file at start time), and only use the
higher-level Endpoint operations when required. This
also makes it easy to start working on a new feature with a simple
design, adding higher-level structure later. For example, I’m
implementing a compressor right now, and the attack and release
times, ratio, and threshold are all just floats on a
Compressor struct. I’ll add endpoints for each of
these parameters later, and doing so will not require any
redesign; the simple version of the build still exists and works,
with the higher-level concept layered neatly on top of it.
Is my clever concurrency model actually kind of dumb?
It might be.
It would take many, many hours of research for me to understand the performance profile of concurrency primitives like mutex locks. And even if I spent those hours, would I be able to account for all the variables? Context switches, cache coherence, syscall overhead, parallelism, probability of lock contention, …? Jackdaw is built to run on different platforms, and the relevance of each of these things varies between them. I therefore design guided by heuristics, like “the use of mutex locks in the real-time audio thread (the DSP thread) should be minimized.” Is that a good heuristic?
Recall that one aspect of my design is the fact that the DSP thread contains only a single locking operation – on the shared queue of asynchronous endpoint value changes – where it might have contained many. At first glance, the single-lock design seems like it would be more performant than a hundred-lock design. But is it?
If the cost of a lock is paid mainly when there is contention, then I might have a problem. Each lock in the hundred-lock design has a relatively low likelihood of contention, since access to the exact matching parameter would need to be requested concurrently on another thread for a conflict to occur; but the single lock has a high likelihood of contention, since every single DSP-thread-owned endpoint write operation must pass through it.
But is it true that “the cost of a lock is paid mainly when there is contention?” That’s another heuristic. And if it is true, how would I compute the overall probability of contention in each of the two models? And are the meager drops of juice2 worth all this squeezing? From a performance perspective, have I just built and blogged about a juice loosener?
I ended my last post with a question that I intended to answer, but this time, I don’t have an answer. It will be months before I reach a phase in development where it’s important to scrutinize designs like this one with an eye toward optimization. For now, I’m happy to have an abstraction that accomplishes all of its other objectives, which turn out to be more important anyway.
This is one of the aforementioned cases where we do not want endpoint writes to be undoable. So,
falseis passed to theundoableparameter.↩︎I haven’t verified this, but based on cursory experimentation I am fairly confident that, as was the case with clip/playhead intersections, the time spent on the DSP thread locking and then working through the queue of endpoint value changes is dwarfed by a single FFT-based effect.↩︎